
热门







在计算机视觉系统中应用Unity合成数据的优势

以人体模型为中心的计算机视觉系统在过去几年里取得了巨大的进步,这在很大程度上得益于大规模的人体数据标记。然而,重要的隐私、法律、安全和伦理问题限制了人体数据的获取渠道。现有的数据集还会有在数据收集和标注时引入的偏差,这会对用这些数据训练的模型产生负面影响。此外,大多数现有的人体数据没有提供对内容多样性、人类活动和姿势以及领域不可知论的适当分析。真实数据的一个新兴替代方法是合成数据,它可以帮助缓解这些问题,这种方案主要应用于以数据为中心的人工智能和用计算机视觉解锁家庭智能应用的解决方案之中。然而,创建合成数据生成器非常具有挑战性,这使得计算机视觉社区无法利用合成数据。此外,合成数据是否有助于取代或补充现有的真实世界数据也是大家一直在讨论的问题,产生这些问题的主要是因为我们缺乏一个高度参数化和高度可操作的数据生成器,该生成器能够被用作模型训练之中。
受到上述挑战的激励,Unity推出了PeopleSansPeople。它是一个以人为中心的数据生成器,包含高度参数化和模拟就绪的3D人资源、参数化照明和相机系统、参数化环境生成器以及完全可操作和可扩展的域随机器。PeopleSansPeople可以在JSON注释文件中生成具有亚像素的完美2D/3D边界框、符合COCO的人体关键点和语义/实例分割遮罩的RGB图像。通过使用PeopleSansPeople和Detectron2 Keypoint R-CNN 变体可以实现基准合成数据训练。
PeopleSansPeople将支持并加速研究合成数据对以人为中心的计算机视觉的作用性。这将解决研究人员在涉及以人作为目标的任务中使用具有域随机化的合成数据,从而扩展了现有和新领域中模拟器功能的空间,如增强现实/虚拟现实、自动驾驶以及人体姿势预估、动作识别和跟踪等。对PeopleSansPeople数据的研究将涉及生成的合成数据,这些数据将模拟与真实(sim2real)传输学习联系起来,并将解决合成数据和真实数据之间的域差。
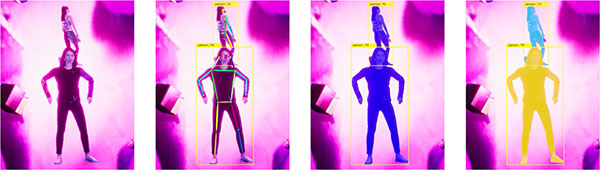
PeopleSansPeople的发布
目前Unity发布了两个版本的PeopleSansPeople:
首先是macOS和Linux的可执行二进制文件,可以用一个可变配置JSON文件生成大规模(1M+)数据集。其包括:
28个不同年龄和种族的3D人体模型,以及不同的服装(拥有28个反照率、28个蒙版和28个法线的21952个独特的服装纹理);
39个动画片段,具有完全随机化的人形放置、大小和旋转,以生成不同排列的人体;
完全参数化的照明设置(位置、颜色、角度和强度)和相机(位置、旋转、视野、焦距)设置;
一组原始对象,用作具有可变纹理的干扰物和遮挡物;和一组1600幅自然图像来自COCO无标签集,充当对象的背景和纹理。
其次,Unity还发布了一个模板项目,通过帮助用户创建自己版本的以人为中心的数据生成器,降低其社区的进入壁垒。用户可以将他们自己获得的3D资产带入这个环境,并通过修改已经存在的域随机化器或定义新的域随机化器来进一步增强其功能。该环境具有上述二进制文件所描述的全部功能:
4个服装颜色不同的示例3D人体模型;
8个示例动画剪辑,具有完全随机化的人形放置、大小和旋转,以生成不同排列的人;和
一组529个来自Unity感知包充当对象的背景和纹理。
PeopleSansPeople域随机化
PeopleSansPeople是一个参数数据生成器,它通过一个简单的JSON配置文件公开了几个变量参数。当然用户也可以直接从Unity环境中更改这些配置。许多领域随机化和环境设计都投入到创建完全参数化的人体模型中。有了这样的参数集,用户能够为人体模型捕捉一些基本的内在和外在变化。通过使用Unity Shader Graph随机化器来改变人体数据资产的服装纹理,这为角色赋予了独特的外观,当然你还可以使用Unity的动画随机器来改变角色的姿势,该工具具有一组不同的动画,涵盖了许多真实的人类动作和姿势。


数据集统计分析
通过使用域随机化,Unity随机生成了500,000幅图像的合成数据集以及上述提及的标签。通过使用这些图像中的490,000个用于训练,10,000个用于验证。我们将合成数据集统计数据与COCO person数据集进行比较。合成数据集比COCO数据集多了一个数量级的实例,也多了一个数量级的带有关键点注释的实例。
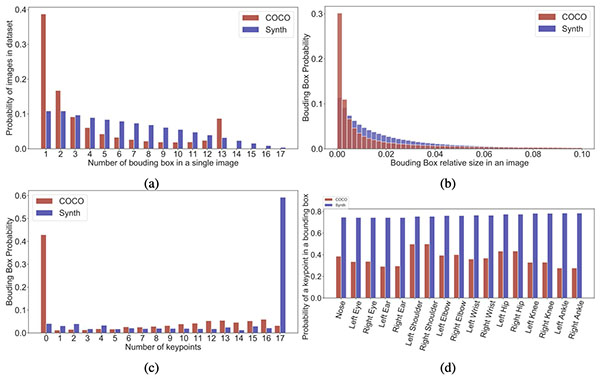
在上图中,显示了三个数据集的边界框占用热图。对于COCO数据集,由于有许多人像和风景图像,我们观察到长方形边界框分布跟随图像的高度和宽度。我们发现大多数盒子靠近大多数图像的中心,而较少向边缘扩展。对于人体合成数据来说,盒子往往更好地占据整个图像框架,因此迫使模型使用整个感受场。

最后,为了量化生成的图像中的人体模型的姿态多样性,我们从角色的末端生成了五个最具代表性关键点的姿态热图。我们观察到1)PeopleSansPeople中人体的分布的姿势包含了COCO中的姿势分布;2)我们合成姿势的分布比COCO更广泛;以及3)在COCO中,大多数人都是面向前方的,导致点密度的“惯用手”不对称,这在合成数据中得到了很好的改善。
PeopleSansPeople基准测试开箱即用
为了获得一组模拟到真实迁移学习的基准结果,我们对各种合成和真实数据集的大小和组合进行了训练,用于人员边界框(bbox)和关键点检测。我们使用平均精度(AP)作为模型性能的主要指标,在COCO人体验证(person val2017)和测试集(test-dev2017)上报告我们的结果。
我们根据随机初始化的权重以及ImageNet预先训练的权重来训练我们的模型。我们没有在任何基准中执行任何模型或数据生成超参数。事实上,我们使用我们直观选择的默认参数范围来生成数据集,并通过从这些范围进行统一采样来强制生成数据。因此,我们的数据生成非常简单。我们在选项卡中显示结果。我们观察到,使用合成数据预训练和真实数据微调,我们的模型比仅在真实数据上训练或使用ImageNet预训练然后在真实数据上微调的模型表现更好。这种效果在真实数据有限的少镜头迁移学习中更强。有了丰富的真实数据,我们仍然观察到合成数据预训练的优势。
需要注意的是,这些结果旨在服务于对PeopleSansPeople数据进行基准测试目的。PeopleSansPeople自带高度参数化的随机器,将定制的随机器集成到其中非常简单。因此,我们预计PeopleSansPeople将能够研究模型训练循环中的超参数调整和数据生成,以优化这些数据的性能,从而解决零触发、少触发以及完全监督的任务。此外,由于合成数据带有丰富的高质量标签,它可以与带有很少或没有注释的真实数据相结合,以实现弱监督训练。
电话:010-50951355 传真:010-50951352 邮箱:sales@souvr.com ;点击查看区域负责人电话
手机:13811546370 / 13720091697 / 13720096040 / 13811548270 /
13811981522 / 18600440988 /13810279720 /13581546145

